Uncertainty and Scenario Forecasting
Source:vignettes/uncertainty-and-scenarios.Rmd
uncertainty-and-scenarios.RmdOverview
bridgr can return point forecasts only, or it can also
compute coefficient uncertainty for the fitted target equation and
prediction intervals for forecasts.
The relevant estimation arguments are:
-
se = FALSE: point forecasts only. -
se = TRUE: compute HAC or Delta-HAC coefficient uncertainty and prediction intervals. -
bootstrap = list(N = 100, block_length = NULL): control the number of predictive simulation paths.block_lengthis only used whenfull_system_bootstrap = TRUE, where it sets the size of the contiguous target-period blocks resampled in each bootstrap draw — larger blocks preserve more temporal dependence. -
full_system_bootstrap = TRUE: replace the default residual-resampling prediction intervals and HAC / Delta-HAC coefficient standard errors with a full-system target-period block bootstrap. Because this refits the full mixed-frequency workflow on every draw, it can be substantially slower.
Fitting a Model with Default Uncertainty
gdp_growth <- suppressMessages(tsbox::ts_na_omit(tsbox::ts_pc(gdp)))
boot_model <- mf_model(
target = gdp_growth,
indic = baro,
indic_predict = "auto.arima",
indic_aggregators = "mean",
indic_lags = 1,
target_lags = 1,
h = 2,
se = TRUE,
bootstrap = list(N = 20, block_length = NULL)
)bridgr computes HAC standard errors for the linear
target equation, or Delta-HAC standard errors when parametric
aggregation weights are estimated jointly. Forecast uncertainty is
obtained by simulating from resampled centered residuals of the fitted
target equation.
Forecast Output
Once the model has been estimated with se = TRUE,
forecast() returns a standardized forecast object with:
meanselowerupperforecast_set- uncertainty metadata
fc <- forecast(boot_model)
fc
#> Mixed-frequency forecast
#> -----------------------------------
#> Target series: gdp_growth
#> Forecast horizon: 2
#> Uncertainty: prediction intervals from residual resampling
#> Simulation paths: 20
#> -----------------------------------
#> time mean se lower_80 upper_80 lower_95 upper_95
#> 1 2023-01-01 0.875 0.742 -0.401 1.859 -0.522 2.120
#> 2 2023-04-01 0.678 0.598 0.035 1.623 -0.317 1.970
fc$bootstrap
#> $requested
#> [1] FALSE
#>
#> $enabled
#> [1] FALSE
#>
#> $N
#> [1] 20
#>
#> $valid_N
#> [1] 0
#>
#> $block_length
#> NULLThe intervals are empirical prediction intervals based on the stored residual-resampling forecast draws.
Reporting Only Forecasts Below a Width Tolerance
In practice prediction intervals widen with horizon. A common
reporting choice is to publish only forecast horizons whose interval is
narrower than some application-specific tolerance — for example, only
publish when the 95% half-width is below a chosen threshold. The example
below applies that rule with a tolerance of 1.5 percentage
points.
forecast_table <- dplyr::tibble(
time = fc$time,
mean = as.numeric(fc$mean),
lower_95 = fc$lower[, "95%"],
upper_95 = fc$upper[, "95%"]
) |>
dplyr::mutate(
half_width_95 = (.data$upper_95 - .data$lower_95) / 2
)
tolerance <- 1.5
dplyr::filter(forecast_table, .data$half_width_95 <= tolerance)
#> # A tibble: 2 × 5
#> time mean lower_95 upper_95 half_width_95
#> <date> <dbl> <dbl> <dbl> <dbl>
#> 1 2023-01-01 0.875 -0.522 2.12 1.32
#> 2 2023-04-01 0.678 -0.317 1.97 1.14Tighten or relax tolerance depending on how much
uncertainty is acceptable in the use case.
Summary Output
The same uncertainty configuration also feeds into
summary().
summary(boot_model)
#> Mixed-frequency model summary
#> -----------------------------------
#> Target series: gdp_growth
#> Target frequency: quarter
#> Forecast horizon: 2
#> Estimation rows: 73
#> Regressors: baro, baro_lag1, gdp_growth_lag1
#> -----------------------------------
#> Target equation coefficients:
#> Estimate HAC SE
#> (Intercept) -6.249 1.424
#> baro 0.151 0.033
#> baro_lag1 -0.084 0.031
#> gdp_growth_lag1 0.012 0.073
#> -----------------------------------
#> Model fit:
#> Statistic Value
#> R-squared 0.682
#> Adjusted R-squared 0.668
#> Residual standard error 0.773
#> -----------------------------------
#> Indicator summary:
#> Frequency Predict Aggregation
#> baro month auto.arima mean
#> -----------------------------------
#> Uncertainty:
#> Coefficient SEs: hac
#> Prediction intervals: residual resampling
#> Simulation paths: 20
#> -----------------------------------The printed summary keeps the same base layout as a point-estimate model and adds the uncertainty section only when uncertainty output is available.
Scenario Forecasting with xreg
If you want to forecast the target under a different future regressor
path, pass a custom xreg object to forecast().
The custom regressor names must match the ones used in the fitted target
equation.
The example below defines a baseline scenario (the indicator continues on its model-implied path) and a negative shock scenario (the indicator drops by 5 points relative to baseline). Both scenarios share the fitted target equation and the same uncertainty method.
make_xreg <- function(level_shift) {
dplyr::tibble(
id = rep(boot_model$xreg_names, each = nrow(boot_model$forecast_base_set)),
time = rep(
boot_model$forecast_base_set$time,
times = length(boot_model$xreg_names)
),
value = c(
boot_model$forecast_base_set$baro + level_shift,
boot_model$forecast_base_set$baro_lag1 + level_shift
)
)
}
fc_baseline <- forecast(boot_model, xreg = make_xreg(0))
fc_shock <- forecast(boot_model, xreg = make_xreg(-5))
scenario_df <- dplyr::bind_rows(
dplyr::tibble(
scenario = "baseline",
time = fc_baseline$time,
mean = as.numeric(fc_baseline$mean),
lower = fc_baseline$lower[, "95%"],
upper = fc_baseline$upper[, "95%"]
),
dplyr::tibble(
scenario = "shock (-5)",
time = fc_shock$time,
mean = as.numeric(fc_shock$mean),
lower = fc_shock$lower[, "95%"],
upper = fc_shock$upper[, "95%"]
)
)
ggplot2::ggplot(
scenario_df,
ggplot2::aes(x = .data$time, color = .data$scenario, fill = .data$scenario)
) +
ggplot2::geom_ribbon(
ggplot2::aes(ymin = .data$lower, ymax = .data$upper),
alpha = 0.2, color = NA
) +
ggplot2::geom_line(ggplot2::aes(y = .data$mean), linewidth = 0.8) +
ggplot2::geom_point(ggplot2::aes(y = .data$mean), size = 2) +
ggplot2::labs(
title = "Forecast under baseline and shock scenarios",
x = NULL, y = "GDP growth forecast"
) +
theme_bridgr()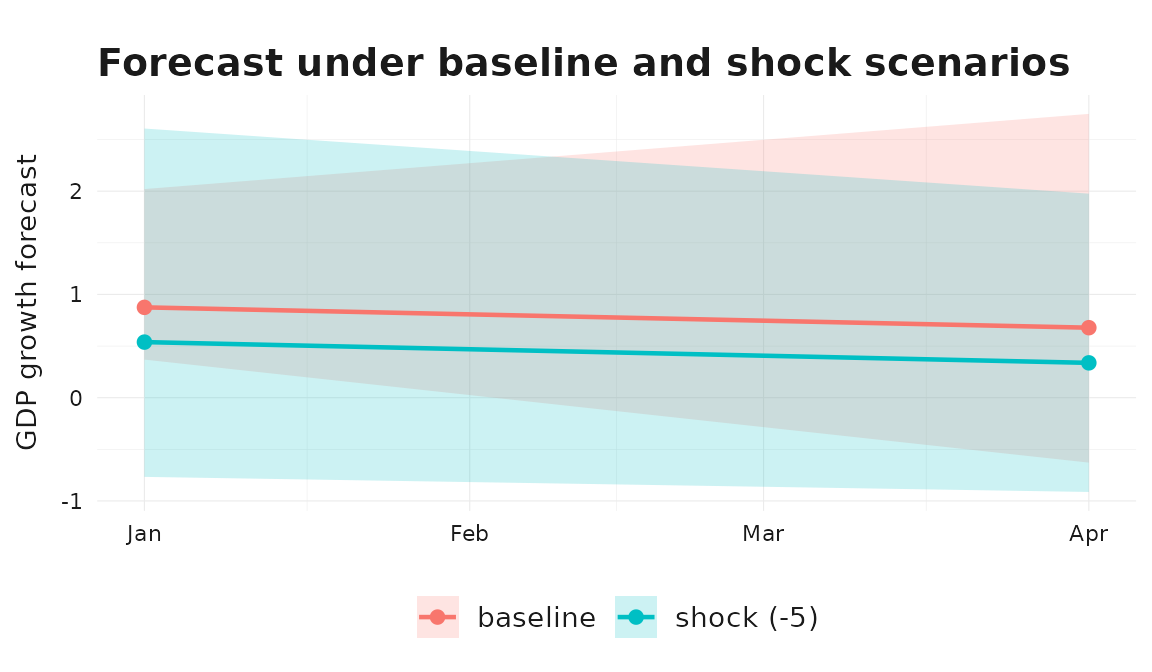
Scenario forecasts reuse the same uncertainty method and evaluate it on the supplied regressor path.
Optional Full-System Bootstrap
If you want to propagate uncertainty through the full mixed-frequency
workflow, including indicator completion and aggregation, set
full_system_bootstrap = TRUE. This can be substantially
slower than the default residual-resampling intervals because each
bootstrap draw re-estimates the full pipeline. In that mode, both the
reported coefficient standard errors and the forecast intervals are
based on the bootstrap draws.
full_model <- mf_model(
target = gdp_growth,
indic = baro,
indic_predict = "auto.arima",
indic_aggregators = "mean",
indic_lags = 1,
target_lags = 1,
h = 2,
se = TRUE,
full_system_bootstrap = TRUE,
bootstrap = list(N = 20, block_length = NULL)
)
forecast(full_model)$bootstrap
#> $requested
#> [1] TRUE
#>
#> $enabled
#> [1] TRUE
#>
#> $N
#> [1] 20
#>
#> $valid_N
#> [1] 20
#>
#> $block_length
#> [1] 5Point Forecasts Only
If you are only interested in point estimates, leave
se = FALSE. In that case, bootstrap is ignored
and forecast() still returns the same object shape, with
NA uncertainty fields.
point_model <- mf_model(
target = gdp_growth,
indic = baro,
indic_predict = "auto.arima",
indic_aggregators = "mean",
indic_lags = 1,
target_lags = 1,
h = 1,
se = FALSE,
bootstrap = list(N = 20)
)
forecast(point_model)
#> Mixed-frequency forecast
#> -----------------------------------
#> Target series: gdp_growth
#> Forecast horizon: 1
#> Uncertainty: point forecast only
#> -----------------------------------
#> time mean
#> 1 2023-01-01 0.875Interpretation
With the default se = TRUE, intervals are
residual-resampling prediction intervals for the fitted target equation,
and coefficient standard errors come from HAC or Delta-HAC estimation.
When full_system_bootstrap = TRUE, both the coefficient
standard errors and the forecast intervals come from a full-system block
bootstrap that resamples target-period blocks from the aligned
mixed-frequency system, refits the workflow on each draw, and evaluates
the resulting future paths.